앞서 ‘주간동아’ 932호에서 좋은 보고서를 작성하는 법을 크게 세 가지 핵심 명제로 정리했다. △보고서 소비자가 누구인지 명확히 할 것 △보고서 소비자가 필요로 하는 사항을 구체적으로 파악할 것 △그 필요 수준을 수치화할 것 등이 그것이다. 보고서 소비자는 작성자가 아니라 결재자이고, 만족하게 해야 할 대상은 내가 아니라 결재자임을 잊지 말아야 한다는 취지였다.
결재자의 합리적 판단을 지원하려면 각 대안에 얽힌 결재자의 이해관계나 중요도를 수치로 보여줄 필요가 있는데, 특히 복잡하고 중요한 사안에 대해서는 수치화를 통해 정량적이고 과학적인 판단을 담아야 결재자의 만족도를 높일 수 있다는 내용도 함께 제시했다. 요컨대 좋은 보고서란 상사의 ‘이해관계’를 수치화한 보고서라는 것이다.
이를 실전에서 활용할 수 있는 단계별 방법 가운데 ‘주간동아’ 932호에서 소개한 세 방법론의 뒤를 이어 4단계에 해당하는 ‘점수화 및 검증법’에 대해 살펴보기로 하자. 처음에는 다소 복잡해 보이지만 실제로는 활용이 쉬우면서도 좋은 결과를 도출하므로 다양한 방면에서 자주 쓸 수 있는 방법이다. 이를 효율적으로 사용하면 이전 방법론에서 해결하지 못한 검증 문제를 해결할 수 있다는 게 특히 강점이다. 즉 판단 기준에 해당하는 (정책)목표와 대안의 중요도를 산출하는 과정에서 전제한 각각의 판단이 논리적 일관성을 유지했는지 여부를 쉬운 방법으로 검증하고 오류를 수정할 수 있는 것이다. ‘주간동아’ 932호에서 점수화법을 설명하면서 활용한 사례를 바탕으로 논의를 진행해보자.
앞서 정부 부처의 복수차관 명칭 문제와 관련해 (정책)목표를 다음처럼 4가지로 정리했다. 이제 이를 2개씩 쌍으로 묶어 ‘어떤 것이 다른 것보다 얼마나 더 중요하다고 생각하는지(또는 선호하는지)’를 일상용어를 써서 판단하면 된다.
가. 업무의 탄력적 배분의 용이성 확보
나. 업무분장 인식의 용이성 확보
다. 명칭을 통한 서열화 방지
라. 부처의 선호도 최대화
예를 들어 ‘업무의 탄력적 배분의 용이성 확보’가 ‘업무분장 인식의 용이성 확보’보다 ‘약간’ 더 중요하다고 판단했다고 해보자. 이때 판단을 ‘약간’ ‘많이’ ‘매우 많이’ ‘극단적으로 많이’ 같은 일상용어를 사용해 판단하고 ‘약간’은 3점, ‘많이’는 5점, ‘매우 많이’는 7점, ‘극단적으로 많이’는 9점 같은 식으로 점수를 부여한다. 덜 중요하게 판단한 쪽에는 무조건 1점을 부여하면 될 것이다. ‘업무의 탄력적 배분의 용이성 확보’가 ‘업무분장 인식의 용이성 확보’보다 ‘약간’ 더 중요하다고 판단했으므로 전자에 3점, 후자에 1점을 부여하면 된다.
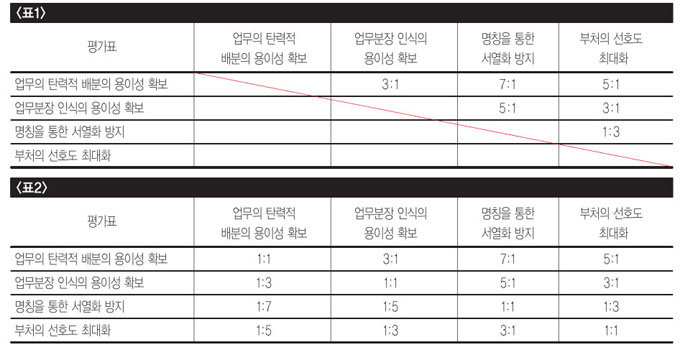 비교대상이 4개인 경우 쌍으로 묶을 수 있는 조합은 총 6개다. 위와 같은 식으로 6개 조합을 모두 평가하고, 이를 예시한 모양의 표로 정리한다. 표에서 각 셀에 ‘행의 요소 : 열의 요소’ 값을 적으면 된다. 예컨대 ‘표1’에서 2행과 3열이 만나는 셀은 ‘업무의 탄력적 배분의 용이성 확보’와 ‘업무분장 인식의 용이성 확보’의 비교이므로 ‘3:1’이라고 적으면 된다. 나머지 5개 조합에 대해서도 ‘표1’과 같이 판단했다고 해보자.
비교대상이 4개인 경우 쌍으로 묶을 수 있는 조합은 총 6개다. 위와 같은 식으로 6개 조합을 모두 평가하고, 이를 예시한 모양의 표로 정리한다. 표에서 각 셀에 ‘행의 요소 : 열의 요소’ 값을 적으면 된다. 예컨대 ‘표1’에서 2행과 3열이 만나는 셀은 ‘업무의 탄력적 배분의 용이성 확보’와 ‘업무분장 인식의 용이성 확보’의 비교이므로 ‘3:1’이라고 적으면 된다. 나머지 5개 조합에 대해서도 ‘표1’과 같이 판단했다고 해보자.
이 표에서 대각선 위에 있는 셀들 값은 동일한 요소의 비교가 된다. 예를 들어 2행과 2열이 만나는 셀은 ‘업무의 탄력적 배분의 용이성 확보’와 ‘업무의 탄력적 배분의 용이성 확보’ 사이의 비교인 셈이다. 따라서 이들은 항상 일대일이 된다. 대각선을 중심으로 아래쪽에 있는 셀들 값은 대칭관계에 있는 위쪽 셀들 값의 역수가 되므로 대각선 위쪽에 자리한 셀들 값만 정하면 나머지는 자동적으로 채울 수 있다. 그 결과 ‘표2’가 만들어진다.
‘표2’의 셀들 값을 분수로 고치고 열의 합계를 구한다. 그다음 열의 합계로 해당 열에 있는 각 셀의 값을 나누면 ‘표3’이 나온다. 이러한 작업 과정을 ‘정규화’라 하는데, 이 작업이 필요한 이유는 열에 있는 각 셀의 합계를 1로 만들기 위해서다.
 그다음 ‘표3’의 오른쪽 부분을 떼어낸 후 각 행의 합계를 내고 이를 다시 정규화하면 드디어 4개 (정책)목표의 중요도가 산출된다. 그 결과가 ‘표4’다.
그다음 ‘표3’의 오른쪽 부분을 떼어낸 후 각 행의 합계를 내고 이를 다시 정규화하면 드디어 4개 (정책)목표의 중요도가 산출된다. 그 결과가 ‘표4’다.
이제 이 표를 읽어보자. 예시한 4개 목표의 중요도가 각각 0.558, 0.263, 0.057, 0.122로 나타났다. 즉 ‘업무의 탄력적 배분의 용이성 확보’와 ‘업무분장 인식의 용이성 확보’가 핵심적인 (정책)목표임을 확인할 수 있는 것이다. 이 두 목표가 가진 중요도만 합해도 82.1%에 달한다. 그 결과를 ‘그래프’처럼 보기 쉽게 표현해 보고서에 첨부하면 결재자가 한층 쉽게 이해할 수 있다.
이러한 수치는 4개 (정책)목표 전체를 대상으로 직관적으로 부여한 임의의 수치가 아니라, 2개씩 쌍으로 묶어 판단한 자료를 이용해 계산하고 산출한 것이다. 따라서 더 합리적인 판단에 가까우므로 그 의미도 더 커지는 것이다. 눈으로 보기엔 다소 까다로운 듯하지만, 그리 어렵지 않게 결과가 나오는 것을 확인할 수 있을 것이다.
이제 남은 것은 이렇게 부여한 중요도가 논리적으로 올바른지를 검증하는 작업이다. 여기에도 약간의 노력이 필요하지만, 차분하게 따라가면 쉽게 이해할 수 있으므로 겁먹을 필요 없다. 먼저 ‘표2’를 활용해 ‘표5’ 왼쪽 부분을 작성한다. ‘표2’의 열 제목 아래에 행을 삽입하고 ‘표4’에서 산출한 중요도를 기입하면 된다. 다음으로 열별로 ‘중요도×해당 열의 셀 값’ 결과를 오른쪽 부분에 기입한다. 마지막으로 행별로 합을 계산한다.
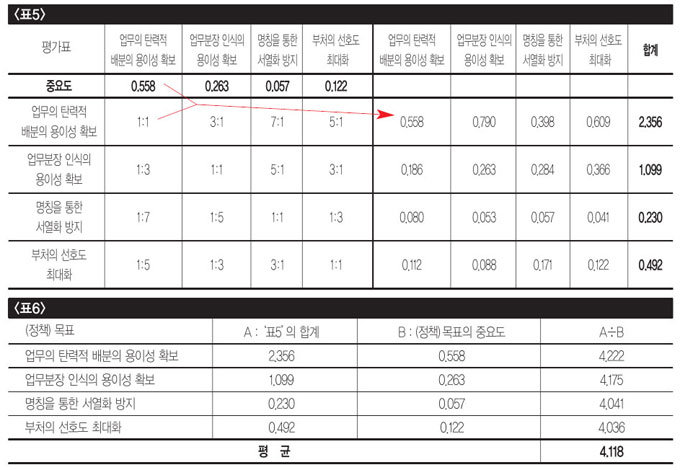 이제 이를 바탕으로 ‘표6’을 만든다. 이 표의 맨 아래 행에 나타나는 평균값이 비교한 대상의 수에 1.1을 곱한 값보다 작으면 대체적으로 논리적 일관성을 유지했다고 생각하면 된다. 다만 비교대상의 수가 4보다 작으면 비교한 대상의 수에 1.05를 곱한 값보다 작은 것이 좋다. ‘표6’의 경우 평균값 4.118은 (정책)목표의 수(4)×1.1인 4.4보다 작으므로 대체적으로 논리적 일관성을 유지했다고 볼 수 있다. 따라서 위 중요도는 다른 중요한 사정으로 변경되지 않는 한 활용에 무리가 없는 셈이다.
이제 이를 바탕으로 ‘표6’을 만든다. 이 표의 맨 아래 행에 나타나는 평균값이 비교한 대상의 수에 1.1을 곱한 값보다 작으면 대체적으로 논리적 일관성을 유지했다고 생각하면 된다. 다만 비교대상의 수가 4보다 작으면 비교한 대상의 수에 1.05를 곱한 값보다 작은 것이 좋다. ‘표6’의 경우 평균값 4.118은 (정책)목표의 수(4)×1.1인 4.4보다 작으므로 대체적으로 논리적 일관성을 유지했다고 볼 수 있다. 따라서 위 중요도는 다른 중요한 사정으로 변경되지 않는 한 활용에 무리가 없는 셈이다.
만일 평균값이 기준치보다 크면 ‘표1’에서 실시한 판단을 하나씩 검토해 수정한 뒤 검증을 통과하게 만들어야 한다. 결정해야 할 사안이 매우 중요하다면 이러한 검증 과정을 거쳐 더 좋은 결론에 도달했을 때 훨씬 큰 장기적 효과를 기대할 수 있다. 당장은 귀찮아 보이는 검증 노력이 매우 큰 보상으로 연결될 수 있다는 뜻이다.
‘점수화 및 검증법’을 활용하려면 이처럼 약간의 계산이 필요하다. 처음에는 익숙지 않을 수 있지만 아주 간단한 계산 과정이므로 그리 어렵지 않게 익힐 수 있다. 특히 액셀 프로그램을 사용하는 독자라면 마우스 클릭 몇 번으로 진행할 수 있을 것이다.
결정해야 할 과제가 간단한 경우는 드물다. 복잡하고 중요하기 때문에 보고서를 작성해야 하고, 결재자 판단이 필요한 것이다. 한눈에 파악할 수 없는 고차원적 문제를 이러한 방식으로 수치화하고 검증한다면 과정과 결과의 객관성이나 투명성, 타당성을 높일 수 있다. 결정해야 할 사안의 중요성이나 복잡성에 걸맞은 수치화된 방법론을 사용할 경우 보고서 품질과 신뢰도가 크게 향상되는 것은 불문가지다. 지면 관계상 근사치로 요약한 ‘점수화 및 검증법’에 대한 자세한 내용을 알고 싶은 독자는 필자가 쓴 책 ‘보고서 작성 이런 것이다’를 참조해도 좋을 것이다.
결재자의 합리적 판단을 지원하려면 각 대안에 얽힌 결재자의 이해관계나 중요도를 수치로 보여줄 필요가 있는데, 특히 복잡하고 중요한 사안에 대해서는 수치화를 통해 정량적이고 과학적인 판단을 담아야 결재자의 만족도를 높일 수 있다는 내용도 함께 제시했다. 요컨대 좋은 보고서란 상사의 ‘이해관계’를 수치화한 보고서라는 것이다.
이를 실전에서 활용할 수 있는 단계별 방법 가운데 ‘주간동아’ 932호에서 소개한 세 방법론의 뒤를 이어 4단계에 해당하는 ‘점수화 및 검증법’에 대해 살펴보기로 하자. 처음에는 다소 복잡해 보이지만 실제로는 활용이 쉬우면서도 좋은 결과를 도출하므로 다양한 방면에서 자주 쓸 수 있는 방법이다. 이를 효율적으로 사용하면 이전 방법론에서 해결하지 못한 검증 문제를 해결할 수 있다는 게 특히 강점이다. 즉 판단 기준에 해당하는 (정책)목표와 대안의 중요도를 산출하는 과정에서 전제한 각각의 판단이 논리적 일관성을 유지했는지 여부를 쉬운 방법으로 검증하고 오류를 수정할 수 있는 것이다. ‘주간동아’ 932호에서 점수화법을 설명하면서 활용한 사례를 바탕으로 논의를 진행해보자.
앞서 정부 부처의 복수차관 명칭 문제와 관련해 (정책)목표를 다음처럼 4가지로 정리했다. 이제 이를 2개씩 쌍으로 묶어 ‘어떤 것이 다른 것보다 얼마나 더 중요하다고 생각하는지(또는 선호하는지)’를 일상용어를 써서 판단하면 된다.
가. 업무의 탄력적 배분의 용이성 확보
나. 업무분장 인식의 용이성 확보
다. 명칭을 통한 서열화 방지
라. 부처의 선호도 최대화
예를 들어 ‘업무의 탄력적 배분의 용이성 확보’가 ‘업무분장 인식의 용이성 확보’보다 ‘약간’ 더 중요하다고 판단했다고 해보자. 이때 판단을 ‘약간’ ‘많이’ ‘매우 많이’ ‘극단적으로 많이’ 같은 일상용어를 사용해 판단하고 ‘약간’은 3점, ‘많이’는 5점, ‘매우 많이’는 7점, ‘극단적으로 많이’는 9점 같은 식으로 점수를 부여한다. 덜 중요하게 판단한 쪽에는 무조건 1점을 부여하면 될 것이다. ‘업무의 탄력적 배분의 용이성 확보’가 ‘업무분장 인식의 용이성 확보’보다 ‘약간’ 더 중요하다고 판단했으므로 전자에 3점, 후자에 1점을 부여하면 된다.
이 표에서 대각선 위에 있는 셀들 값은 동일한 요소의 비교가 된다. 예를 들어 2행과 2열이 만나는 셀은 ‘업무의 탄력적 배분의 용이성 확보’와 ‘업무의 탄력적 배분의 용이성 확보’ 사이의 비교인 셈이다. 따라서 이들은 항상 일대일이 된다. 대각선을 중심으로 아래쪽에 있는 셀들 값은 대칭관계에 있는 위쪽 셀들 값의 역수가 되므로 대각선 위쪽에 자리한 셀들 값만 정하면 나머지는 자동적으로 채울 수 있다. 그 결과 ‘표2’가 만들어진다.
‘표2’의 셀들 값을 분수로 고치고 열의 합계를 구한다. 그다음 열의 합계로 해당 열에 있는 각 셀의 값을 나누면 ‘표3’이 나온다. 이러한 작업 과정을 ‘정규화’라 하는데, 이 작업이 필요한 이유는 열에 있는 각 셀의 합계를 1로 만들기 위해서다.
이제 이 표를 읽어보자. 예시한 4개 목표의 중요도가 각각 0.558, 0.263, 0.057, 0.122로 나타났다. 즉 ‘업무의 탄력적 배분의 용이성 확보’와 ‘업무분장 인식의 용이성 확보’가 핵심적인 (정책)목표임을 확인할 수 있는 것이다. 이 두 목표가 가진 중요도만 합해도 82.1%에 달한다. 그 결과를 ‘그래프’처럼 보기 쉽게 표현해 보고서에 첨부하면 결재자가 한층 쉽게 이해할 수 있다.
이러한 수치는 4개 (정책)목표 전체를 대상으로 직관적으로 부여한 임의의 수치가 아니라, 2개씩 쌍으로 묶어 판단한 자료를 이용해 계산하고 산출한 것이다. 따라서 더 합리적인 판단에 가까우므로 그 의미도 더 커지는 것이다. 눈으로 보기엔 다소 까다로운 듯하지만, 그리 어렵지 않게 결과가 나오는 것을 확인할 수 있을 것이다.
이제 남은 것은 이렇게 부여한 중요도가 논리적으로 올바른지를 검증하는 작업이다. 여기에도 약간의 노력이 필요하지만, 차분하게 따라가면 쉽게 이해할 수 있으므로 겁먹을 필요 없다. 먼저 ‘표2’를 활용해 ‘표5’ 왼쪽 부분을 작성한다. ‘표2’의 열 제목 아래에 행을 삽입하고 ‘표4’에서 산출한 중요도를 기입하면 된다. 다음으로 열별로 ‘중요도×해당 열의 셀 값’ 결과를 오른쪽 부분에 기입한다. 마지막으로 행별로 합을 계산한다.
만일 평균값이 기준치보다 크면 ‘표1’에서 실시한 판단을 하나씩 검토해 수정한 뒤 검증을 통과하게 만들어야 한다. 결정해야 할 사안이 매우 중요하다면 이러한 검증 과정을 거쳐 더 좋은 결론에 도달했을 때 훨씬 큰 장기적 효과를 기대할 수 있다. 당장은 귀찮아 보이는 검증 노력이 매우 큰 보상으로 연결될 수 있다는 뜻이다.
‘점수화 및 검증법’을 활용하려면 이처럼 약간의 계산이 필요하다. 처음에는 익숙지 않을 수 있지만 아주 간단한 계산 과정이므로 그리 어렵지 않게 익힐 수 있다. 특히 액셀 프로그램을 사용하는 독자라면 마우스 클릭 몇 번으로 진행할 수 있을 것이다.
결정해야 할 과제가 간단한 경우는 드물다. 복잡하고 중요하기 때문에 보고서를 작성해야 하고, 결재자 판단이 필요한 것이다. 한눈에 파악할 수 없는 고차원적 문제를 이러한 방식으로 수치화하고 검증한다면 과정과 결과의 객관성이나 투명성, 타당성을 높일 수 있다. 결정해야 할 사안의 중요성이나 복잡성에 걸맞은 수치화된 방법론을 사용할 경우 보고서 품질과 신뢰도가 크게 향상되는 것은 불문가지다. 지면 관계상 근사치로 요약한 ‘점수화 및 검증법’에 대한 자세한 내용을 알고 싶은 독자는 필자가 쓴 책 ‘보고서 작성 이런 것이다’를 참조해도 좋을 것이다.















