소셜미디어에서는 다양한 콘텐츠가 아주 빠르게 확산한다. 이런 특성 때문에 이용자는 글로벌한 혹은 특정 지역의 인기 있는 주제를 쉽게 알 수 있다. 또한 소셜미디어의 빅데이터는 기업에서 발생하는 빅데이터에 비해 상대적으로 접근이 용이하다. 더욱이 그 콘텐츠 속에는 개인의 솔직한 생각이 고스란히 담겨 있어 기업들이 사회 트렌드 변화나 고객 마음을 읽는 데 혹은 입소문 마케팅에 매우 유용하게 활용하고 있다.
하지만 전통 미디어와 달리 소셜미디어에서는 쏟아지는 정보를 검증하는 게 어렵고 별도의 검증 절차도 없다는 단점이 있다. 따라서 검증되지 않은 잘못된 정보가 대규모로 신속하게 확산해 사회에 커다란 해를 끼칠 가능성이 상존한다. 예를 들면 2009년 3월 신종 인플루엔자A(H1N1·신종플루)가 멕시코와 미국 등지에서 발생한 뒤 전 세계 40개국으로 퍼져 확진환자가 9830명에 달하고 사망자도 수백 명에 달한 적이 있다. 그 당시 소셜네트워크서비스(SNS) 트위터를 통해 돼지고기를 먹으면 신종플루에 감염될 수 있다는 잘못된 정보가 수백만 명의 사용자에게 전파됐고, 이로 인해 소셜미디어의 전 네트워크에 걸쳐 패닉이 발생했다.
소셜미디어 인기가 높아지고 확산의 잠재력이 커지면서 소셜미디어에서 전파되는 루머와 진짜 정보를 구별하는 것이 더욱 중요해졌다. 그런데 2013년 말 차미영 KAIST(한국과학기술원) 교수 연구팀은 ‘소셜 미디어에서 루머 전파의 중요한 특징’이라는 제목의 논문에서 트위터 등 SNS에 나도는 루머를 90% 이상 정확하게 가려낼 수 있는 방법을 제시해 세계적인 주목을 받았다. 이번 글에서는 이 연구의 주요 내용을 소개한다.
 루머의 전파는 주기적 급등
루머의 전파는 주기적 급등
지금까지 루머 확산에 관한 연구는 주로 주어진 정보의 신뢰도를 계량화하거나 루머의 발생을 탐지하려는 측면에 중점을 둬왔다. 하지만 차 교수 연구팀은 루머를 확인하기 위한 새로운 접근법을 제시했는데 그것은 루머 확산의 시간적, 구조적, 언어적 특성을 분석하는 것이었다. 분석에 사용된 데이터는 트위터가 시작된 2006년 3월부터 2009년 9월까지 3년 반 동안의 자료였다. 그중 최소한 60개 이상 포스트가 붙은 102개 주제를 선정해 사용자 5400만 명의 트위트 17억 개와 그들 사이 폴로 링크 19억 개를 분석했다. 이 102개 주제 중 루머는 47개, 진짜 정보는 55개였는데 루머 특징은 다음과 같았다.
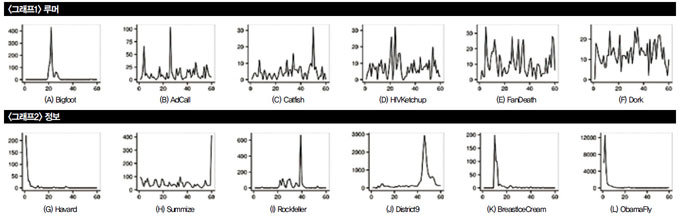
먼저 루머 확산의 시간적 특성은 60일간의 시계열 분석 결과 ‘그래프’와 같았다. 각 그래프에서 x축은 날짜(days), y축은 그 주제에 대한 트위트 수를 나타낸다. 루머의 시계열 패턴은 윗줄 그래프(그래프1)에, 진짜 정보의 시계열 패턴은 아랫줄(그래프2)에 제시됐다. ‘그래프1’에서 쉽게 볼 수 있듯이 루머의 전파는 여러 개의 주기적인 급등(spikes)을 나타내는데, 이는 소문을 퍼뜨리는 사람들이 기회를 노려 루머를 또다시 전파하려는 행동을 반복하기 때문이었다. 반면 진짜 정보의 전파는 단 한 개의 두드러진 급등만 나타냈는데, 이는 정보를 전달한 후에는 이미 정보 전달의 목적이 달성됐으므로 다른 후속 행동이 없음을 의미했다.
다음으로 루머와 진짜 정보가 구조적으로 어떻게 다르게 확산하는지를 나타내면 오른쪽 그림과 같다.
 그림에서 ‘A’는 빅풋(Bigfoot) 추적자들이 빅풋 사체를 발견했다는 루머의 확산 네트워크인데, 빅풋은 미국과 캐나다 로키산맥 일대에서 목격된다는 ‘털이 많은 거인’이다. ‘B’는 정보기술(IT) 기업인 서미즈(Summize)를 트위터가 인수한다는 진짜 정보의 확산 네트워크다. 그림에서 볼 수 있듯 루머는 단독으로 전파되는 비율, 즉 트위트가 다른 사람들에 의해 언급되거나 리트위트되지 않는 비율이 높았는데 이는 대부분의 경우 폴로어들이 그 메시지를 무시한다는 것을 의미했다. 또한 루머는 영향력이 낮은 사람에게서 영향력이 높은 사람에게 전파되는 비율이 높았는데, 이는 루머를 퍼뜨리는 사람들이 다른 사람들의 주의를 끌려고 하기 때문이었다.
그림에서 ‘A’는 빅풋(Bigfoot) 추적자들이 빅풋 사체를 발견했다는 루머의 확산 네트워크인데, 빅풋은 미국과 캐나다 로키산맥 일대에서 목격된다는 ‘털이 많은 거인’이다. ‘B’는 정보기술(IT) 기업인 서미즈(Summize)를 트위터가 인수한다는 진짜 정보의 확산 네트워크다. 그림에서 볼 수 있듯 루머는 단독으로 전파되는 비율, 즉 트위트가 다른 사람들에 의해 언급되거나 리트위트되지 않는 비율이 높았는데 이는 대부분의 경우 폴로어들이 그 메시지를 무시한다는 것을 의미했다. 또한 루머는 영향력이 낮은 사람에게서 영향력이 높은 사람에게 전파되는 비율이 높았는데, 이는 루머를 퍼뜨리는 사람들이 다른 사람들의 주의를 끌려고 하기 때문이었다.
‘안 돼, 아니, 절대로’가 자주 쓰이면 루머
루머와 진짜 정보의 언어적 특성을 보면 먼저 루머는 사용자가 문장 속에서 ‘안 돼, 아니, 절대로(no, not, never)’ 등과 같은 부정적 단어나 ‘그러나, ~없이, 제외하다(but, without, exclude)’ 같은 배타적 단어를 사용할 가능성이 훨씬 높았다. 반면 진짜 정보는 ‘사랑, 친절한, 달콤한(love, nice, sweet)’ 등과 같이 긍정적인 감정을 나타내는 단어를 많이 포함했다. 또한 사용자는 루머와 관련한 내용에 대해 ‘아마도, 추측건대, 어쩌면(maybe, guess, perhaps)’ 같은 잠정적 표현이나 ‘생각하다, 알다, 고려하다(think, know, consider)’ 같은 인지적인 행동을 취할 가능성이 높았다. 반면 진짜 정보와 관련한 내용에 대해서는 ‘관점, 봤다, 보다(view, saw, see)’ 같은 확인적인 행동을 할 가능성이 높았다.
소셜미디어 분석의 가치는 다양한 콘텐츠가 아주 빠르게 확산하는 가운데서 트렌드 변화를 나타내는 ‘사실(fact)’을 찾아내는 것이다. 하지만 많은 경우 이 사실이 루머와 섞여 검증도 되지 않은 채 신속하게 확산되기도 한다. 차 교수팀의 연구는 소셜미디어의 연속적인 데이터를 분석해 루머 확산의 근본적인 과정을 연구한 최초의 논문으로서 의의가 크다.
특히 구조적이고 언어적인 특징에 추가해 시간적 특성도 고려함으로써 루머 연구의 새로운 접근 방법을 제시했다. 일반적으로 소셜미디어의 시간적 특성은 구조적 혹은 언어적 특성보다 더 쉽게 분석 가능하다. 또한 차 교수 연구팀은 이러한 세 가지 특징을 기반으로 주어진 정보가 루머인지 진짜 정보인지를 예측하는 확률 모델을 개발했다. 이 모델은 루머와 진짜 정보를 가려내는 정확도가 약 90%에 달했는데 이는 기존 연구보다 훨씬 높은 적중률이었다.
하지만 전통 미디어와 달리 소셜미디어에서는 쏟아지는 정보를 검증하는 게 어렵고 별도의 검증 절차도 없다는 단점이 있다. 따라서 검증되지 않은 잘못된 정보가 대규모로 신속하게 확산해 사회에 커다란 해를 끼칠 가능성이 상존한다. 예를 들면 2009년 3월 신종 인플루엔자A(H1N1·신종플루)가 멕시코와 미국 등지에서 발생한 뒤 전 세계 40개국으로 퍼져 확진환자가 9830명에 달하고 사망자도 수백 명에 달한 적이 있다. 그 당시 소셜네트워크서비스(SNS) 트위터를 통해 돼지고기를 먹으면 신종플루에 감염될 수 있다는 잘못된 정보가 수백만 명의 사용자에게 전파됐고, 이로 인해 소셜미디어의 전 네트워크에 걸쳐 패닉이 발생했다.
소셜미디어 인기가 높아지고 확산의 잠재력이 커지면서 소셜미디어에서 전파되는 루머와 진짜 정보를 구별하는 것이 더욱 중요해졌다. 그런데 2013년 말 차미영 KAIST(한국과학기술원) 교수 연구팀은 ‘소셜 미디어에서 루머 전파의 중요한 특징’이라는 제목의 논문에서 트위터 등 SNS에 나도는 루머를 90% 이상 정확하게 가려낼 수 있는 방법을 제시해 세계적인 주목을 받았다. 이번 글에서는 이 연구의 주요 내용을 소개한다.
지금까지 루머 확산에 관한 연구는 주로 주어진 정보의 신뢰도를 계량화하거나 루머의 발생을 탐지하려는 측면에 중점을 둬왔다. 하지만 차 교수 연구팀은 루머를 확인하기 위한 새로운 접근법을 제시했는데 그것은 루머 확산의 시간적, 구조적, 언어적 특성을 분석하는 것이었다. 분석에 사용된 데이터는 트위터가 시작된 2006년 3월부터 2009년 9월까지 3년 반 동안의 자료였다. 그중 최소한 60개 이상 포스트가 붙은 102개 주제를 선정해 사용자 5400만 명의 트위트 17억 개와 그들 사이 폴로 링크 19억 개를 분석했다. 이 102개 주제 중 루머는 47개, 진짜 정보는 55개였는데 루머 특징은 다음과 같았다.
먼저 루머 확산의 시간적 특성은 60일간의 시계열 분석 결과 ‘그래프’와 같았다. 각 그래프에서 x축은 날짜(days), y축은 그 주제에 대한 트위트 수를 나타낸다. 루머의 시계열 패턴은 윗줄 그래프(그래프1)에, 진짜 정보의 시계열 패턴은 아랫줄(그래프2)에 제시됐다. ‘그래프1’에서 쉽게 볼 수 있듯이 루머의 전파는 여러 개의 주기적인 급등(spikes)을 나타내는데, 이는 소문을 퍼뜨리는 사람들이 기회를 노려 루머를 또다시 전파하려는 행동을 반복하기 때문이었다. 반면 진짜 정보의 전파는 단 한 개의 두드러진 급등만 나타냈는데, 이는 정보를 전달한 후에는 이미 정보 전달의 목적이 달성됐으므로 다른 후속 행동이 없음을 의미했다.
다음으로 루머와 진짜 정보가 구조적으로 어떻게 다르게 확산하는지를 나타내면 오른쪽 그림과 같다.
‘안 돼, 아니, 절대로’가 자주 쓰이면 루머
루머와 진짜 정보의 언어적 특성을 보면 먼저 루머는 사용자가 문장 속에서 ‘안 돼, 아니, 절대로(no, not, never)’ 등과 같은 부정적 단어나 ‘그러나, ~없이, 제외하다(but, without, exclude)’ 같은 배타적 단어를 사용할 가능성이 훨씬 높았다. 반면 진짜 정보는 ‘사랑, 친절한, 달콤한(love, nice, sweet)’ 등과 같이 긍정적인 감정을 나타내는 단어를 많이 포함했다. 또한 사용자는 루머와 관련한 내용에 대해 ‘아마도, 추측건대, 어쩌면(maybe, guess, perhaps)’ 같은 잠정적 표현이나 ‘생각하다, 알다, 고려하다(think, know, consider)’ 같은 인지적인 행동을 취할 가능성이 높았다. 반면 진짜 정보와 관련한 내용에 대해서는 ‘관점, 봤다, 보다(view, saw, see)’ 같은 확인적인 행동을 할 가능성이 높았다.
소셜미디어 분석의 가치는 다양한 콘텐츠가 아주 빠르게 확산하는 가운데서 트렌드 변화를 나타내는 ‘사실(fact)’을 찾아내는 것이다. 하지만 많은 경우 이 사실이 루머와 섞여 검증도 되지 않은 채 신속하게 확산되기도 한다. 차 교수팀의 연구는 소셜미디어의 연속적인 데이터를 분석해 루머 확산의 근본적인 과정을 연구한 최초의 논문으로서 의의가 크다.
특히 구조적이고 언어적인 특징에 추가해 시간적 특성도 고려함으로써 루머 연구의 새로운 접근 방법을 제시했다. 일반적으로 소셜미디어의 시간적 특성은 구조적 혹은 언어적 특성보다 더 쉽게 분석 가능하다. 또한 차 교수 연구팀은 이러한 세 가지 특징을 기반으로 주어진 정보가 루머인지 진짜 정보인지를 예측하는 확률 모델을 개발했다. 이 모델은 루머와 진짜 정보를 가려내는 정확도가 약 90%에 달했는데 이는 기존 연구보다 훨씬 높은 적중률이었다.